
Retrieval-Augmented Generation (RAG) applications represent a sophisticated use of embedding models, where the goal is to enhance generative models with the ability to retrieve and utilize external information. In optimizing RAG systems, we encounter two main pathways: tuning the generative model itself or optimizing the embedding model used for information retrieval. The focus here will be on the latter, emphasizing why optimizing your embeddings model is crucial for the success of RAG applications. For those new to this concept, or if you're seeking a more detailed introduction to what embedding models are and their significance, we highly recommend checking out our article .
The importance of embedding tuning in RAG systems cannot be overstated. Without the ability to retrieve relevant information, even the most advanced generative model is left flying blind, unable to provide answers that are accurate or pertinent to the user's query. There are two clear advantages to fine-tuning your embeddings for your specific task. First, it is resource efficient. The alternative to obtaining accurate answers through embedding tuning is to increase the "K number" or the number of information chunks the system considers. By optimizing the embeddings, we can reduce the need for a high K number, leading to significant improvements in computational efficiency and database management. This not only lessens the load on your hardware but also streamlines the retrieval process, making for a leaner, more efficient system.
Second, embedding tuning enhances time efficiency. A lower K number requirement means that the correct answers can be provided more quickly, improving not just the system's performance but also the user experience. In fast-paced environments where time is of the essence, the ability to swiftly deliver accurate and relevant information is invaluable. By investing in the optimization of your embeddings model, you're not just upgrading the technical capabilities of your RAG application; you're also offering a smoother, more responsive experience to your users, which can be a critical factor in the success of your application.
For tuning embeddings it's important to start by prepping your data, make sure you have train and validation data as always. Let's start with my favorite loss function for RAG:
It's very similar to ContrastiveLoss but more powerful, all you need to provide is [Query, Chunk Good, label= 1] and [Query, Chunk Bad, label= 0] . Where Chunk Good is the one that you want to be relevant and Chunk Bad is the one that you want to be less relevant. Imagine we have a case where our similarity search results look like this, where c1 is irrelevant for our RAG thus Bad chunk and c5 is relevant this a good chunk.


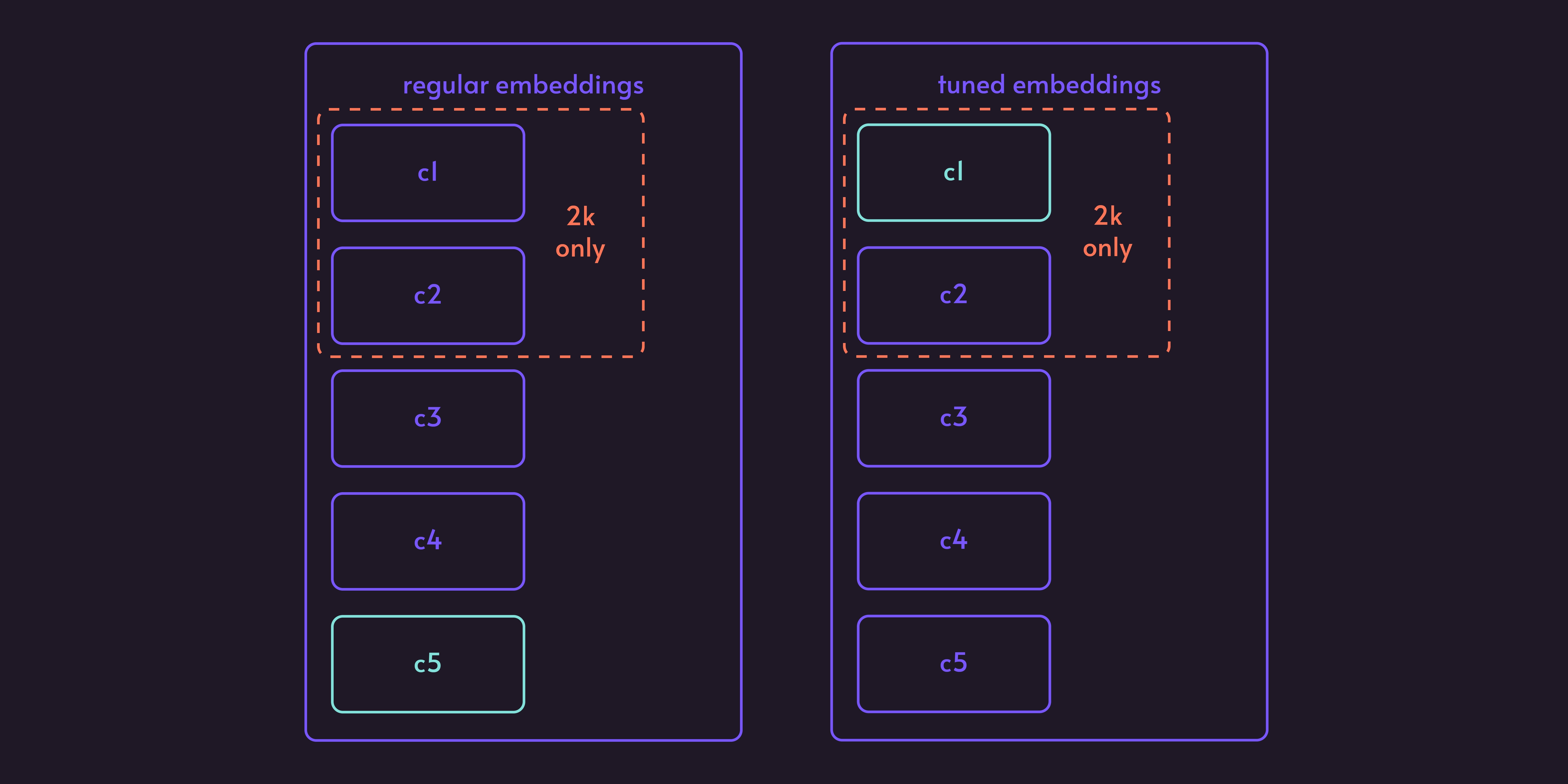
After tuning our embeddings with Contrastive Loss we can get results like this.
Our c5 is now in front and c1 at the back. This way, if we will use only one chunk,
we still will get the chunk we need.
What makes Contrastive Loss special is that we can directly provide examples of
both relevant and less relevant data points. If we fine tune only positive examples,
we might make negative examples even more positive, but this way we can actually tune
our embeddings in a way that we want.
In terms of cat metaphors:
You show the cat the treat on the desired shelf (good) and another treat on a lower shelf (bad) at the same time.
The cat gets the good treat only if it jumps to the higher shelf. This teaches the cat to distinguish
the desired shelf from others.
This is probably the simplest one to tune with, just find good examples and tune on them [Question, Good Chunk]. This will allow you to boost those chunks. But be careful that it may not impact chunks that you are unhappy with as much as you want. This is a good loss function to choose if you don't have many negative examples.
In terms of cat metaphors:
You have a video of a perfectly executed jump to the desired shelf (ideal form). The cat
practices jumping, and you praise it the closer its jump gets to the ideal form in the video.
This trains the cat to refine its jumping technique towards the perfect form.
This is a good loss function if you have many negative examples. You will need to provide triplets like [Query, Good Chunk, Bad Chunk] you can also leave out bad chunks, but I recommend using bad chunks here. It's better than cosine loss due to faster learning.
In terms of cat metaphors:
You have other cats with different jumping styles (clumsy jump, slow climb). The cat jumps, and all
the other cats jump too. You give the cat a treat only if its jump is the most similar to reaching
the desired shelf compared to the others. This encourages the cat to learn the most efficient way
to reach the shelf by observing the failures of others.

Now lets look at a code of OnlineContrastiveLoss implementation.
First we load dependencies:
from sentence_transformers import SentenceTransformer
import json
from torch.utils.data import DataLoader
from sentence_transformers import InputExampleNext we can load desired model from Huggingface that we want to tune:
model_id = "WhereIsAI/UAE-Large-V1"
model = SentenceTransformer(model_id)
Lets load the data:
Should be a dict with “queries”: [unique_id: query], “corpus”: [unique_id: chunk/context],
“relevant_docs: [query_unique_id: [curpus_good_unique_id, corpus_bad_unique_id]]
TRAIN_DATASET_FPATH = './train_data.json'
VAL_DATASET_FPATH = './val_data.json'
BATCH_SIZE = 10
with open(TRAIN_DATASET_FPATH, 'r+') as f:
train_dataset = json.load(f)
with open(VAL_DATASET_FPATH, 'r+') as f:
val_dataset = json.load(f)We prep our data for sentence transformers:
dataset = train_dataset
corpus = dataset['corpus']
queries = dataset['queries']
relevant_docs = dataset['relevant_docs']
examples = []
for query_id, query in queries.items():
node_id = relevant_docs[query_id][0]
node_id2 = relevant_docs[query_id][1]
text2 = corpus[node_id2]
text = corpus[node_id]
example = InputExample(texts=[query, text], label = 1)
example2 = InputExample(texts=[query, text2], label = 0)
examples.extend([example, example2])We load data
loader = DataLoader(
examples, batch_size=BATCH_SIZE
)Define loss
from sentence_transformers import losses
loss = losses.OnlineContrastiveLoss(model)Define Eval
from sentence_transformers.evaluation import InformationRetrievalEvaluator
dataset = val_dataset
corpus = dataset['corpus']
queries = dataset['queries']
relevant_docs = dataset['relevant_docs']
evaluator = InformationRetrievalEvaluator(queries, corpus, relevant_docs)Train embeddings
EPOCHS = 10
warmup_steps = int(len(loader) * EPOCHS * 0.1)
model.fit(
train_objectives=[(loader, loss)],
epochs=EPOCHS,
warmup_steps=warmup_steps,
output_path='exp_finetune',
show_progress_bar=True,
evaluator=evaluator,
evaluation_steps=10,
)Save model
import shutil
shutil.make_archive('model-embeddings', 'zip', 'exp_finetune')
Here is
a script
that I used to prep my data.
To use your custom embeddings inside DocsGPT:
1. Navigate to application/vectorstore/base.py
2. Load your chosen embedding by specifying model_name and point to the saved path
embeddings_factory[embeddings_name](
model_name="./model/all-mpnet-base-v2",
model_kwargs={"device": "cpu"},
)Embedding optimization is an important part of a successful production RAG system. By fine-tuning your embeddings, you can improve the accuracy and efficiency of information retrieval, leading to better user experiences and reduced computational costs.
Get in touch