
In the rapidly evolving landscape of artificial intelligence, the rise of Generative AI and Large Language Models (LLMs) is creating exciting new possibilities and uses. This transformation is largely driven by the growing importance of embedding models, especially in tasks like improving search functions or developing interactive chat experiences that use specific user data. This article explores the crucial role that embeddings play in these sophisticated AI applications. Join us as we journey through the world of embeddings, their importance in LLMs/RAG processes, and practical insights from our experiences at DocsGPT.
Embeddings are essentially numeric vector representations of various data elements (sentences, images, words, etc.) transforming them into a format that machines can understand and process efficiently. This transformation is crucial as it enables the mapping of semantically related items, fostering a more nuanced and contextually aware interaction between AI models and the vast ocean of information available.
The true power of embeddings lies in their ability to retrieve and provide relevant context. When a user interacts with these models, the provided prompt is enhanced by the contextual richness that embeddings bring to the table. For instance, text embeddings are the driving force behind search engines like Google, enabling them to sift through vast amounts of data and retrieve relevant information. However, the effectiveness of these embeddings hinges on the quality of the embedding model used.

It's crucial to note that different embeddings are suited for different types of data and contexts. For example, models like Glove offer high processing speed but may lack context awareness. This highlights the importance of continually updating and selecting the most appropriate embeddings for specific applications to ensure optimal performance. Keeping up with the latest developments in embeddings is not just beneficial but essential in the rapidly evolving field of LLMs.
The Massive Text Embedding Benchmark (MTEB) stands out for assessing the performance of various text embedding models across a broad range of tasks. MTEB incorporates 56 datasets in 112 languages covering 8 unique tasks, and it compiles over 2000 results on its leaderboard. This variety in languages and tasks is crucial as it underlines the fact that the efficacy of embedding models can differ dramatically depending on the specific application, dataset, and language involved.
After highlighting this diversity, it becomes evident that while MTEB offers a comprehensive overview, it is also crucial to conduct task-specific testing with embeddings. Given the unique demands and nuances of each application, custom tests are recommended to normalize results and ensure that the chosen embedding is precisely tailored to the requirements of your specific task.
Choosing the right embedding is a pivotal decision in the realm of Large Language Models (LLMs). This choice can significantly impact the model's ability to understand and process natural language effectively. The primary challenge lies in matching the embedding's strengths to the specific requirements of the LLM and the nature of the data it will process.

Different embeddings possess varying capabilities in handling linguistic nuances. For instance, some embeddings might struggle with text that includes special characters or unconventional spellings. An illustrative example of this can be seen in the performance of the all-mpnet-base-v2 embedding model. This model faced difficulties in retrieving relevant information for queries involving the term "back-end" spelled with a hyphen. However, when the embedding model was switched to bge-large-en, the retrieval accuracy improved significantly.
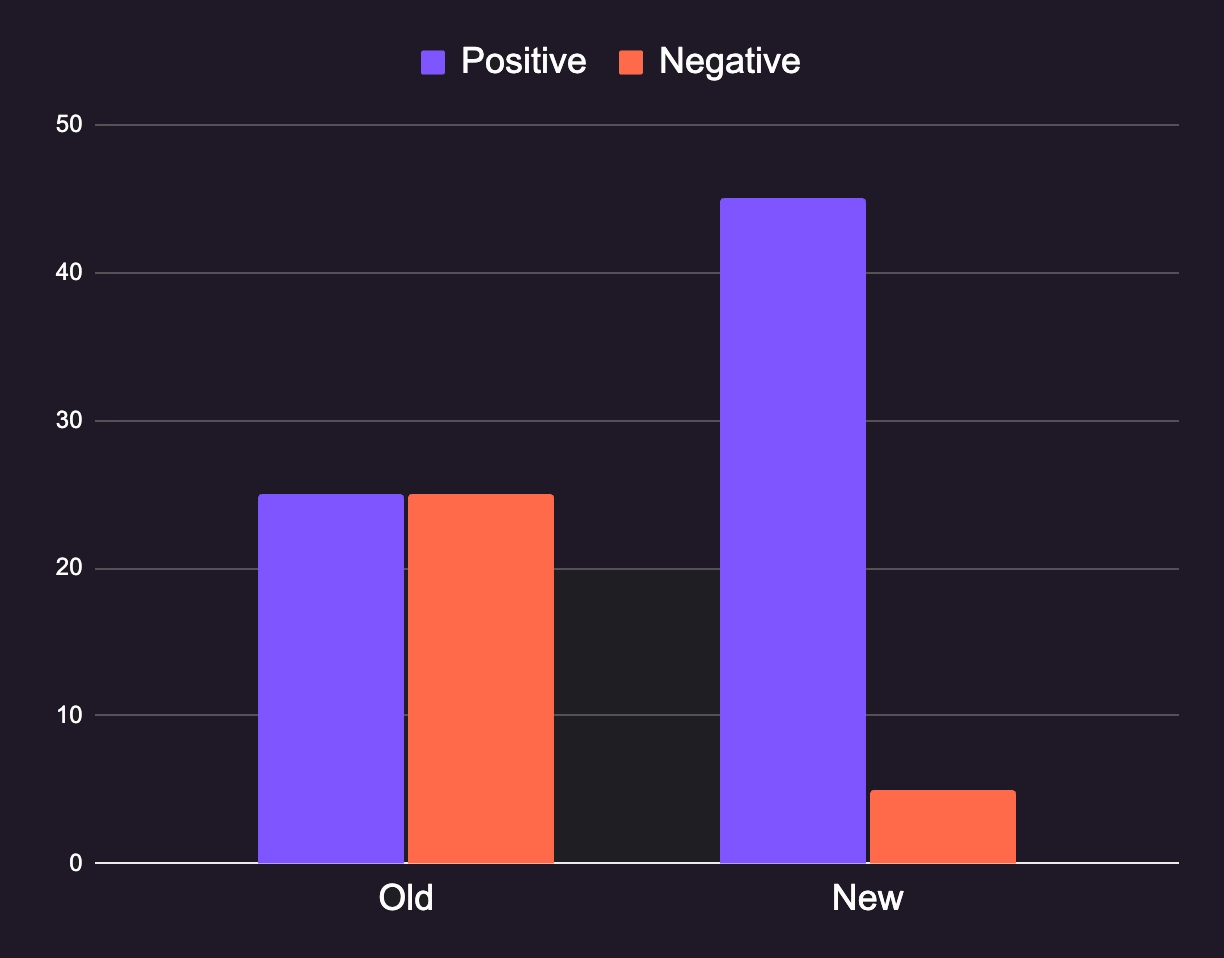
The custom deployment of DocsGPT for one of our clients serves as a prime example of how the right embedding can dramatically enhance an LLM's performance. In this case study, switching to a more suitable embedding model led to a more than 50% increase in positive user feedback.
This enhancement in search and retrieval capabilities was quantitatively evident in internal benchmarks. Prior to the embedding change, only half of the searches yielded relevant results. However, post-embedding optimization, the relevancy rate soared to 90%.
The recent integration of MongoDB Atlas as a supported vector database for DocsGPT has brought forth a set of compelling advantages, particularly in the realms of data management and efficiency. MongoDB Atlas, known for its robust capabilities in CRUD (Create, Read, Update, Delete) operations, simplifies the process of updating and managing existing data, a vital aspect in the dynamic environment of language models.
One of the standout features of MongoDB Atlas in this context is its adeptness in handling multiple embeddings. The ability to link various embeddings directly with one or more Large Language Models (LLMs) without the necessity for separate collections or tables is a powerful feature. This approach not only streamlines the data architecture but also eliminates the need for data duplication, a common challenge in traditional database setups. By facilitating the storage and management of multiple embeddings, it allows for a more seamless and flexible interaction between different LLMs and their respective embeddings.
Consequently, this integration paves the way for a more efficient and scalable approach to handling the complex data needs of DocsGPT, ensuring that the system remains agile and adaptable to diverse requirements and datasets.
1. In your .env file set VECTOR_STORE to mongodb, or pass this env variable to your
environment in any other way.
2. Configure Index on MongoDB Atlas.
Go to your database
Open Atlas Search tab, Create new, choose Altas Vector search, choose the collection,
Paste this in your index config, in numDimensions ensure it fits the embeddings that you chose.
{
"fields": [
{
"numDimensions": 1536,
"path": "embedding",
"similarity": "cosine",
"type": "vector"
},
{
"path": "store",
"type": "filter"
}
]
}
Click next and create Index.
Once index finishes running, it will be ready to use with your application.
The effective use of embedding models with LLMs is crucial for enhancing their performance and capabilities. This article highlights the importance of carefully selecting embeddings and the advantages of MongoDB Atlas in managing complex data needs. We encourage readers to explore various options in their LLM projects for better efficiency and results.
At Arc53, we are equipped to assist you in finding the right embeddings, training custom LLMs, or setting up DocsGPT to meet your specific needs. Reach out to us for specialized support and insights that can help maximize the potential of your AI tools and projects. Let's navigate the exciting world of AI together, leveraging the right tools and expertise for success.
Get in touch