
Welcome to the first edition of AI Spotlight, our new recurring format dedicated to shining a light on the fascinating world of Artificial Intelligence. In this series, we aim to keep you abreast of the latest developments and breakthroughs in AI technology, featuring in-depth analyses and insights into cutting-edge models. Whether a model has set a new benchmark, introduced an innovative feature, or simply caught our attention for its unique capabilities, AI Spotlight will bring it into focus. Today, we delve into four models that are redefining the boundaries of what AI can achieve: Claude 3 Opus, Cohere Command R, Gemini 1.5 Pro, and Grok.
Claude 3 Opus introduces a suite of advancements that redefine AI model capabilities. Claude 3 significantly reduces unnecessary refusals, demonstrating a deeper understanding of user queries. It excels in delivering highly accurate responses across various complex queries, marking a significant upgrade from Claude 2.1. Anthropic promises to open 1 million tokens input, for now max context window is 200K tokens.
Claude published a comprehensive table showcasing the performance of Opus across a variety of popular AI evaluation benchmarks, where it impressively surpassed both GPT-4 and Gemini 1.0 (Ultra and Pro). The benchmarks covered a broad range of areas including undergraduate level expert knowledge (MMLU), graduate level expert reasoning (GPQA), basic mathematics (GSM8K), along with other well-regarded metrics such as HellaSwag and the ARC-Challenge.
While benchmarks offer a snapshot of a model's capabilities, they often don't capture the full scope of its effectiveness. Recognizing this, we also turned our attention to LMSYS Chatbot Arena, a crowdsourced platform dedicated to the open evaluation of Large Language Models (LLMs). With over 400,000 human preference votes collected, LLMs are ranked using the Elo rating system. In this rigorous and comprehensive evaluation, Opus claimed the top spot, further cementing its status as a leading figure in the AI landscape.

From what I've seen using Claude 3 Opus, it feels just as smart as GPT-4. The cool thing is, Opus doesn’t beat around the bush with its answers—they're straight to the point but still give you the details when you need them. It’s pretty good with code, and it seems to get what I'm asking for in the prompts really well. When it comes to speed, it's quicker than GPT-4 but not as fast as the smaller models. Also, it handles tasks in other languages like a pro, making it super versatile. All in all, Opus has been a solid performer in my book, especially for how well it juggles different languages and detailed tasks.
Command R is specifically designed for complex conversational exchanges and excels in Retrieval Augmented Generation (RAG) applications, making it a good match for DocsGPT on paper. Command R's proficiency in more than 10 languages, including English, French, and Spanish, amplifies its appeal for multilingual tasks, offering broad international utility. One of the distinguishing features of Command R is its ability to produce responses backed by citations, drawing from document snippets to lend credibility to its outputs. This, coupled with its capacity to employ tools such as code interpreters for executing complex operations, solidifies Command R as an all-purpose LLM.

From my time with Command R, I've noticed it's a bit behind GPT-4 and Opus in terms of performance, but it's not lagging far behind. In English, it holds its own pretty well, which is great. However, when I tested it in some of the other languages Cohere mentioned, it didn’t quite hit the mark for me. But, considering what you pay for it, Command R isn’t a bad deal at all.
Gemini 1.5 Pro is focusing on improving how models understand and process long contexts. It's now capable of handling content up to 1 million tokens in length, pushing the boundaries of what AI models can comprehend and respond to. The introduction of the Mixture-of-Experts (MoE) architecture is a key feature of this new model, enabling it to utilize specific neural network pathways for increased efficiency and task-specific performance.
Google has stated that Gemini 1.5 Pro performs better than its previous versions in their internal tests, positioning it alongside the high-performing Gemini 1.0 Ultra. While these internal benchmarks highlight its potential, the true test of its capabilities will come from direct comparison with competing models. As we await the release of Gemini 1.5 Ultra and further community-led benchmarking, Gemini 1.5 Pro stands as a promising step forward in handling complex and lengthy data inputs.
Grok-1 is another model with the Mixture-of-Experts architecture that was made accessible to the public recently. xAI has also released the weights for its enormous 314 billion parameter model. Distributed under the Apache 2.0 license, Grok-1 contributes to the open-source AI development movement. Currently, Grok-1 is not fine-tuned for specific applications and tasks, including Retrieval Augmented Generation. The model's vast size is remarkable, requiring about 10 A100 GPUs for inference, posing a challenge for further fine-tuning due to its computational demands.
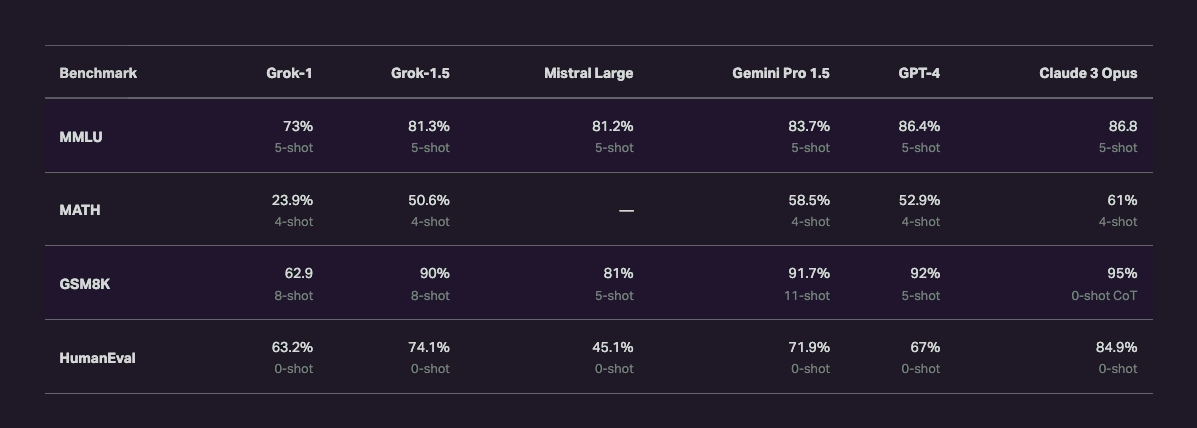
Despite the initial version of Grok being somewhat unoptimized, xAI have already announced the upcoming release of Grok-1.5, which they claim has achieved impressive benchmarks. Surpassing Mistral Large in all shared tests and even outperforming GPT-4 in the HumanEval benchmark, Grok-1.5 appears to be a significant step up from its predecessor. As we eagerly await Grok-1.5's release, we are keen to explore its enhancements and potential firsthand, hopeful for the advancements this new iteration will bring to the AI landscape.
As we conclude this edition of AI Spotlight, it's clear that the landscape of artificial intelligence continues to evolve at an astonishing pace. Each model brings its own unique strengths to the table, promising to unlock new capabilities and applications that were previously beyond our reach. In a move to bring these cutting-edge developments closer to our audience, we are excited to announce that we have integrated both Command R and Claude 3 Opus into the live version of DocsGPT. Their addition not only enhances the platform's versatility and effectiveness but also allows you to directly observe and evaluate these models in real-world applications.
Check out the live versionAs we move forward, we eagerly await further developments from the Gemini and Grok projects. The journey of AI innovation is far from over, and we at Arc53 are committed to keeping you informed and engaged with every breakthrough and milestone along the way.